Imagine you have a few data pipelines to schedule. Simplest solution would be cronjob. Time goes by and next thing you know, you have around 50 pipelines to manage. The fun starts when you have to hunt down which pipeline doesn’t run normally. And by then it would be super hard to do tracing if you haven’t set up logging and monitoring.
Luckily there are tools we can use to improve the situation. Task orchestrators are born exactly for this, to schedule and monitor pipelines. These days there are more bells and whistles, such as backfilling and sensor triggers. Some also integrate with data catalog tools and provide table specs and data lineage.
Sounds familiar? If you have been looking into Airflow, this is exactly what it does. But there are other alternatives too, and in this post we’re going to find out what Dagster Cloud can do. (Spoiler: yay CI/CD).
Dagster architecture
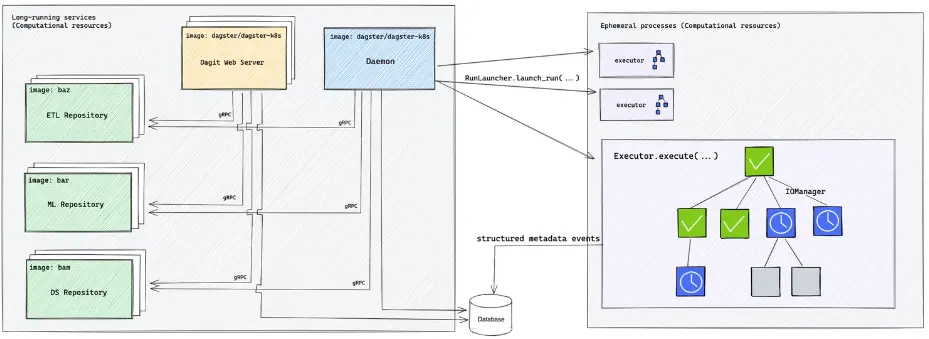
This is how dagster work. But to set all this up yourself, you need to at least:
- Package each dagster repository into its own image
- Setup dagit container for UI
- Set up dagster daemon instance to trigger tasks
- Set up postgres for dagster metastore
- Set I/O manager to use blob storage
- Set up default executors and concurrent run limits
- CI/CD to update code and base dagster image
And if you have multiple users, you need to set up the auth yourself too.
Enter Dagster Cloud
But folks at Dagster know people are finding it very tricky to set it up, so they provide a few cloud offerings, one of which is serverless. This essentially means you only need to supply the code and set up CI/CD, and Dagster would provide a VM to run your tasks.
To test it out, you can sign up on Dagster Cloud and follow instructions here.
Cool dagster features
Branch preview
Frontend usually set up CI/CD to return a preview of a PR, now you can do the same with dagster!
This means your team can preview what the DAG would look like, or give it a spin before deploying to prod 🚀.
Multiple teams you say?
Imagine working in an organization with many teams. Some teams might use dbt, another might use spark. Sometimes each team has different virtual environment. Even if you can use the same setup for multiple teams, over time the number of pipelines would grow significantly, which means it’s harder to manage. But we can set up a dagster repo for each team, then link them together via Dagster Cloud for a single control plane.
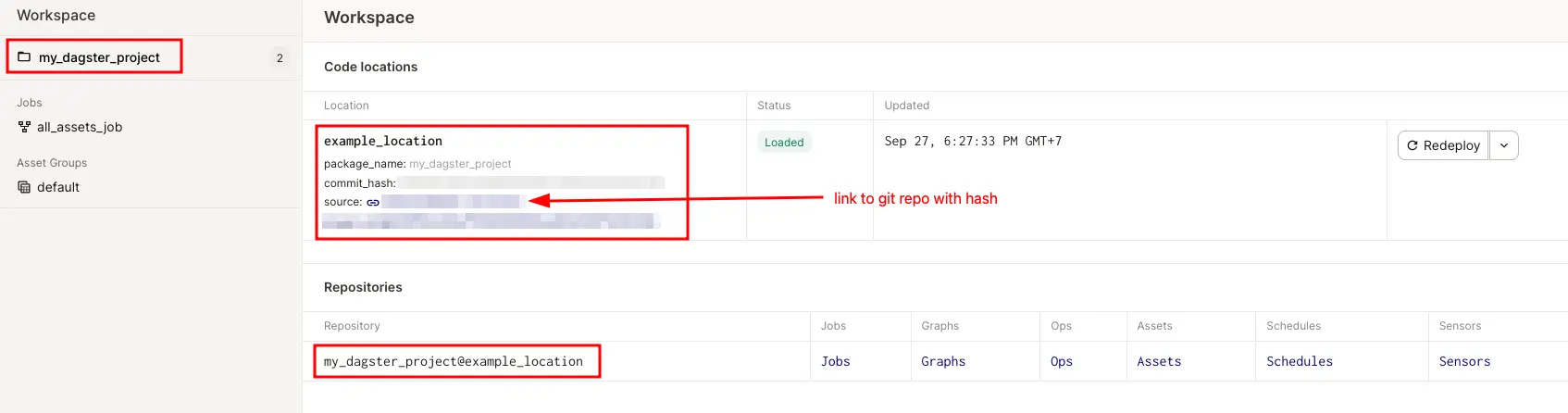
Notice each code location has attached git hash. Yay tracing!
Table lineage
Running multiple pipelines are cool. But if you update this pipeline, do you also need to update downstream pipelines? I’m sure you can have a list of pipelines dependency somewhere, but it’s so much more convenient to see it right from dagster.
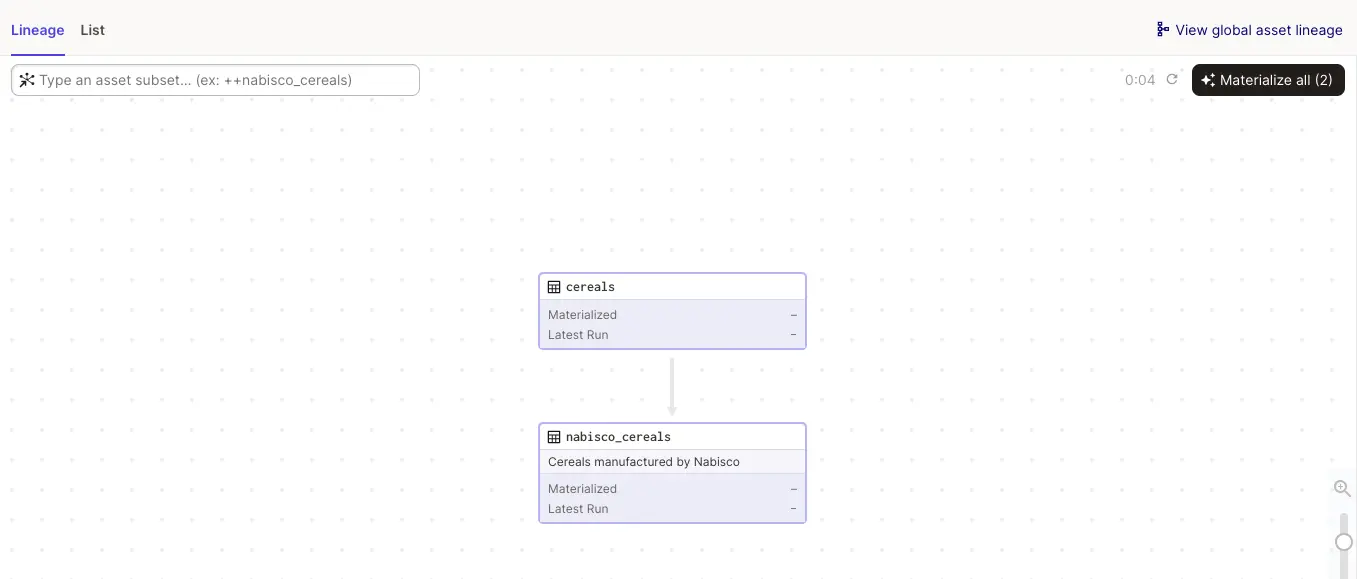
Notice the Materialize button on top right. This means you can trigger run on an upstream table, and it would automatically update downstream tables.
Dagster has more features, don’t forget to check out their docs (it’s well written)!